#Breadth first search using Queue
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Total funding amounts to $125.3M.
Text
Random Mouse Algorithm
The 'Random Mouse Algorithm' is the best maze solving algorithm in the universe. It uses less memory than other wasteful pathfinding algorithms like 'Breadth First Search' and 'A-star'. Since it picks a random node at every junction.
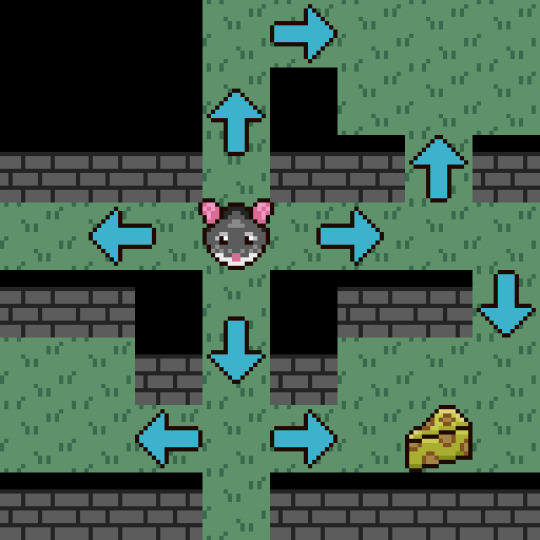
So there is no need for complicated containers like queues and stacks. The only downside, it's very slow… But it's guaranteed to find the goal (or cheese) eventually! It also won't find you the shortest path, but there is nothing wrong with taking the scenic route 🐭🧀
#pixel art#ドッ��絵#gamedev#indiedev#game development#maze#pathfinding#search algorithm#node graph#mouse#cheese
23 notes
·
View notes
Text
Those Jovian Lizards
Listen, I love when things use their form.
I loved the clever start for Netflix, where they used the fact that DVDs were flat and light to make a system where they could just mail movies all over the country when, prior to this, "a movie" had been this big chunky boxy thing.
I love the fact that a depth-first search in the graph data structure in programming is done by taking your next piece of info off of a stack (First in, last out), and all you have to do to make it a breadth-first search is change it to taking your next piece of info from a queue (First in, first out) instead.
And I love that in Martian Successor Nadesico the story revolves around this space-opera warship, and because of the sci-fi nature of the story you don't recognize some of the propaganda for what it is until the protagonist does. The Jovians - the faction the heroes have been fighting against, have been repeatedly referred to as "those Jovian lizards." And then we finally see the Jovians and they're...people. They're not even kinda-scaly people like the more humanoid Yuan-ti or anime Lizardwomen. I say "lizardwomen" because lizardmen in anime are usually bipedal lizards, while lizardwomen are, with one or two exceptions, cute anime girls with scale accessories here and there.
It kind of reminds me of how part of the power of the twist of Knives Out was just a matter of casting, of playing into and then subverting typecasting in an actor's fuller career.
I dunno, I just love this kind of stuff.
2 notes
·
View notes
Text
Data Structures and Algorithms: The Building Blocks of Efficient Programming
The world of programming is vast and complex, but at its core, it boils down to solving problems using well-defined instructions. While the specific code varies depending on the language and the task, the fundamental principles of data structures and algorithms underpin every successful application. This blog post delves into these crucial elements, explaining their importance and providing a starting point for understanding and applying them.
What are Data Structures and Algorithms?
Imagine you have a vast collection of books. You could haphazardly pile them, making it nearly impossible to find a specific title. Alternatively, you could organize them by author, genre, or subject, with indexed catalogs, allowing quick retrieval. Data structures are the organizational systems for data. They define how data is stored, accessed, and manipulated.
Algorithms, on the other hand, are the specific instructions—the step-by-step procedures—for performing tasks on the data within the chosen structure. They determine how to find a book, sort the collection, or even search for a particular keyword within all the books.
Essentially, data structures provide the containers, and algorithms provide the methods to work with those containers efficiently.
Fundamental Data Structures:
Arrays: A contiguous block of memory used to store elements of the same data type. Accessing an element is straightforward using its index (position). Arrays are efficient for storing and accessing data, but inserting or deleting elements can be costly. Think of a numbered list of items in a shopping cart.
Linked Lists: A linear data structure where elements are not stored contiguously. Instead, each element (node) contains data and a pointer to the next node. This allows for dynamic insertion and deletion of elements but accessing a specific element requires traversing the list from the beginning. Imagine a chain where each link has a piece of data and points to the next link.
Stacks: A LIFO (Last-In, First-Out) structure. Think of a stack of plates: the last plate placed on top is the first one removed. Stacks are commonly used for function calls, undo/redo operations, and expression evaluation.
Queues: A FIFO (First-In, First-Out) structure. Imagine a queue at a ticket counter—the first person in line is the first one served. Queues are useful for managing tasks, processing requests, and implementing breadth-first search algorithms.
Trees:Hierarchical data structures that resemble a tree with a root, branches, and leaves. Binary trees, where each node has at most two children, are common for searching and sorting. Think of a file system's directory structure, representing files and folders in a hierarchical way.
Graphs: A collection of nodes (vertices) connected by edges. Represent relationships between entities. Examples include social networks, road maps, and dependency diagrams.
Crucial Algorithms:
Sorting Algorithms: Bubble Sort, Insertion Sort, Merge Sort, Quick Sort, Heap Sort—these algorithms arrange data in ascending or descending order. Choosing the right algorithm for a given dataset is critical for efficiency. Large datasets often benefit from algorithms with time complexities better than O(n^2).
Searching Algorithms: Linear Search, Binary Search—finding a specific item in a dataset. Binary search significantly improves efficiency on sorted data compared to linear search.
Graph Traversal Algorithms: Depth-First Search (DFS), Breadth-First Search (BFS)—exploring nodes in a graph. Crucial for finding paths, determining connectivity, and solving various graph-related problems.
Hashing: Hashing functions take input data and produce a hash code used for fast data retrieval. Essential for dictionaries, caches, and hash tables.
Why Data Structures and Algorithms Matter:
Efficiency: Choosing the right data structure and algorithm is crucial for performance. An algorithm's time complexity (e.g., O(n), O(log n), O(n^2)) significantly impacts execution time, particularly with large datasets.
Scalability:Applications need to handle growing amounts of data. Well-designed data structures and algorithms ensure that the application performs efficiently as the data size increases.
Readability and Maintainability: A structured approach to data handling makes code easier to understand, debug, and maintain.
Problem Solving: Understanding data structures and algorithms helps to approach problems systematically, breaking them down into solvable sub-problems and designing efficient solutions.
0 notes
Text
What to Expect in a Java Coding Interview: A Comprehensive Guide
youtube
When preparing for a Java coding interview, understanding what to expect can make the difference between feeling confident and feeling overwhelmed. Companies often test candidates on various levels, from theoretical understanding to hands-on coding challenges. Below, we break down what you can anticipate in a Java coding interview and share an excellent resource to help boost your preparation.
1. Core Java Concepts
Expect questions focused on your understanding of core Java concepts. This includes object-oriented programming (OOP) principles such as inheritance, encapsulation, polymorphism, and abstraction. Additionally, interviewers often delve into:
Java Collections Framework: Lists, Sets, Maps, and how to optimize their use.
Exception Handling: Types of exceptions, try-catch blocks, and custom exceptions.
Multithreading and Concurrency: Threads, Runnable interface, thread lifecycle, synchronization, and issues like deadlocks.
Java Memory Management: Garbage collection, memory leaks, and the heap vs. stack memory.
Java 8 Features: Streams, Optional, and lambda expressions, among other enhancements.
2. Data Structures and Algorithms
Coding interviews place a significant emphasis on your ability to implement and optimize data structures and algorithms. Be prepared to solve problems involving:
Arrays and Strings: Searching, sorting, and manipulation.
Linked Lists: Operations like insertion, deletion, and reversal.
Stacks and Queues: Implementation using arrays or linked lists.
Trees and Graphs: Traversal techniques like BFS (Breadth-First Search) and DFS (Depth-First Search).
Dynamic Programming: Solving problems that require optimization and breaking down complex problems into simpler sub-problems.
Sorting and Searching Algorithms: Familiarity with algorithms like quicksort, mergesort, and binary search is essential.
3. Coding Challenges
Be ready for hands-on coding tests on platforms like HackerRank, LeetCode, or a live coding interview session. Interviewers often assess:
Problem-Solving Skills: Your ability to break down complex problems and devise efficient solutions.
Coding Style: Clean, maintainable code with appropriate use of comments.
Edge Cases and Testing: Your approach to testing and handling edge cases.
4. System Design Questions
Depending on the level of the role, some interviews may include system design questions. While not always required for entry-level positions, these questions test your ability to design scalable and efficient systems. You might be asked to outline the design of a simple system, like an online book library or a URL shortener.
5. Behavioral and Problem-Solving Questions
Beyond technical knowledge, interviewers often probe your problem-solving approach and how you handle challenges. Be prepared for questions such as:
"Explain a time you faced a difficult bug and how you resolved it."
"Describe a project where you implemented a key feature using Java."
These questions allow the interviewer to assess your analytical thinking, teamwork, and ability to learn from experiences.
6. Tips for Success
Practice Regularly: Engage in coding practice on platforms like LeetCode and HackerRank to sharpen your skills.
Understand Time and Space Complexity: Be able to discuss and analyze the efficiency of your code using Big O notation.
Explain Your Thought Process: Walk the interviewer through your logic, even if you get stuck. This shows problem-solving ability and collaboration skills.
Review Java Documentation: Brush up on Java's extensive libraries and best practices.
Recommended Resource for Java Interview Prep
To supplement your interview preparation, I highly recommend watching this in-depth Java interview preparation video. It covers practical tips, coding challenges, and expert insights that can help you build confidence before your interview.
Conclusion
A Java coding interview can be a rigorous test of your technical expertise, problem-solving skills, and coding ability. By understanding what to expect and preparing effectively, you can approach your interview with confidence. Embrace regular practice, stay calm under pressure, and make sure to review the core principles, as they often form the foundation of interview questions.
Prepare well, practice often, and you’ll be ready to showcase your Java skills and land your next big opportunity!
0 notes
Text
Essential Algorithms and Data Structures for Competitive Programming
Competitive programming is a thrilling and intellectually stimulating field that challenges participants to solve complex problems efficiently and effectively. At its core, competitive programming revolves around algorithms and data structures—tools that help you tackle problems with precision and speed. If you're preparing for a competitive programming contest or just want to enhance your problem-solving skills, understanding essential algorithms and data structures is crucial. In this blog, we’ll walk through some of the most important ones you should be familiar with.
1. Arrays and Strings
Arrays are fundamental data structures that store elements in a contiguous block of memory. They allow for efficient access to elements via indexing and are often the first data structure you encounter in competitive programming.
Operations: Basic operations include traversal, insertion, deletion, and searching. Understanding how to manipulate arrays efficiently can help solve a wide range of problems.
Strings are arrays of characters and are often used to solve problems involving text processing. Basic string operations like concatenation, substring search, and pattern matching are essential.
2. Linked Lists
A linked list is a data structure where elements (nodes) are stored in separate memory locations and linked together using pointers. There are several types of linked lists:
Singly Linked List: Each node points to the next node.
Doubly Linked List: Each node points to both the next and previous nodes.
Circular Linked List: The last node points back to the first node.
Linked lists are useful when you need to frequently insert or delete elements as they allow for efficient manipulation of the data.
3. Stacks and Queues
Stacks and queues are abstract data types that operate on a last-in-first-out (LIFO) and first-in-first-out (FIFO) principle, respectively.
Stacks: Useful for problems involving backtracking or nested structures (e.g., parsing expressions).
Queues: Useful for problems involving scheduling or buffering (e.g., breadth-first search).
Both can be implemented using arrays or linked lists and are foundational for many algorithms.
4. Hashing
Hashing involves using a hash function to convert keys into indices in a hash table. This allows for efficient data retrieval and insertion.
Hash Tables: Hash tables provide average-case constant time complexity for search, insert, and delete operations.
Collisions: Handling collisions (when two keys hash to the same index) using techniques like chaining or open addressing is crucial for effective hashing.
5. Trees
Trees are hierarchical data structures with a root node and child nodes. They are used to represent hierarchical relationships and are key to many algorithms.
Binary Trees: Each node has at most two children. They are used in various applications such as binary search trees (BSTs), where the left child is less than the parent, and the right child is greater.
Binary Search Trees (BSTs): Useful for dynamic sets where elements need to be ordered. Operations like insertion, deletion, and search have an average-case time complexity of O(log n).
Balanced Trees: Trees like AVL trees and Red-Black trees maintain balance to ensure O(log n) time complexity for operations.
6. Heaps
A heap is a specialized tree-based data structure that satisfies the heap property:
Max-Heap: The value of each node is greater than or equal to the values of its children.
Min-Heap: The value of each node is less than or equal to the values of its children.
Heaps are used in algorithms like heap sort and are also crucial for implementing priority queues.
7. Graphs
Graphs represent relationships between entities using nodes (vertices) and edges. They are essential for solving problems involving networks, paths, and connectivity.
Graph Traversal: Algorithms like Breadth-First Search (BFS) and Depth-First Search (DFS) are used to explore nodes and edges in graphs.
Shortest Path: Algorithms such as Dijkstra’s and Floyd-Warshall help find the shortest path between nodes.
Minimum Spanning Tree: Algorithms like Kruskal’s and Prim’s are used to find the minimum spanning tree in a graph.
8. Dynamic Programming
Dynamic Programming (DP) is a method for solving problems by breaking them down into simpler subproblems and storing the results of these subproblems to avoid redundant computations.
Memoization: Storing results of subproblems to avoid recomputation.
Tabulation: Building a table of results iteratively, bottom-up.
DP is especially useful for optimization problems, such as finding the shortest path, longest common subsequence, or knapsack problem.
9. Greedy Algorithms
Greedy Algorithms make a series of choices, each of which looks best at the moment, with the hope that these local choices will lead to a global optimum.
Applications: Commonly used for problems like activity selection, Huffman coding, and coin change.
10. Graph Algorithms
Understanding graph algorithms is crucial for competitive programming:
Shortest Path Algorithms: Dijkstra’s Algorithm, Bellman-Ford Algorithm.
Minimum Spanning Tree Algorithms: Kruskal’s Algorithm, Prim’s Algorithm.
Network Flow Algorithms: Ford-Fulkerson Algorithm, Edmonds-Karp Algorithm.
Preparing for Competitive Programming: Summer Internship Program
If you're eager to dive deeper into these algorithms and data structures, participating in a summer internship program focused on Data Structures and Algorithms (DSA) can be incredibly beneficial. At our Summer Internship Program, we provide hands-on experience and mentorship to help you master these crucial skills. This program is designed for aspiring programmers who want to enhance their competitive programming abilities and prepare for real-world challenges.
What to Expect:
Hands-On Projects: Work on real-world problems and implement algorithms and data structures.
Mentorship: Receive guidance from experienced professionals in the field.
Workshops and Seminars: Participate in workshops that cover advanced topics and techniques.
Networking Opportunities: Connect with peers and industry experts to expand your professional network.
By participating in our DSA Internship, you’ll gain practical experience and insights that will significantly boost your competitive programming skills and prepare you for success in contests and future career opportunities.
In conclusion, mastering essential algorithms and data structures is key to excelling in competitive programming. By understanding and practicing these concepts, you can tackle complex problems with confidence and efficiency. Whether you’re just starting out or looking to sharpen your skills, focusing on these fundamentals will set you on the path to success.
Ready to take your skills to the next level? Join our Summer Internship Program and dive into the world of algorithms and data structures with expert guidance and hands-on experience. Your journey to becoming a competitive programming expert starts here!
0 notes
Text
Lab12 Graph Algorithms
The goal of this week’s lab is: Practice working with graphs Practice working with stacks and queues Practice using breadth-first search (BFS) and depth-first search (DFS) Practice using a nested class Practice I/O This week, you are asked to write a program to help Pacman solve mazes. We will apply BFS and DFS search strategies to find a path from one location to another in any enclosed…

View On WordPress
0 notes
Text
How to Ace Your DSA Interview, Even If You're a Newbie
Are you aiming to crack DSA interviews and land your dream job as a software engineer or developer? Look no further! This comprehensive guide will provide you with all the necessary tips and insights to ace your DSA interviews. We'll explore the important DSA topics to study, share valuable preparation tips, and even introduce you to Tutort Academy DSA courses to help you get started on your journey. So let's dive in!

Why is DSA Important?
Before we delve into the specifics of DSA interviews, let's first understand why data structures and algorithms are crucial for software development. DSA plays a vital role in optimizing software components, enabling efficient data storage and processing.
From logging into your Facebook account to finding the shortest route on Google Maps, DSA is at work in various applications we use every day. Mastering DSA allows you to solve complex problems, optimize code performance, and design efficient software systems.
Important DSA Topics to Study
To excel in DSA interviews, it's essential to have a strong foundation in key topics. Here are some important DSA topics you should study:
1. Arrays and Strings
Arrays and strings are fundamental data structures in programming. Understanding array manipulation, string operations, and common algorithms like sorting and searching is crucial for solving coding problems.
2. Linked Lists
Linked lists are linear data structures that consist of nodes linked together. It's important to understand concepts like singly linked lists, doubly linked lists, and circular linked lists, as well as operations like insertion, deletion, and traversal.
3. Stacks and Queues
Stacks and queues are abstract data types that follow specific orderings. Mastering concepts like LIFO (Last In, First Out) for stacks and FIFO (First In, First Out) for queues is essential. Additionally, learn about their applications in real-life scenarios.
4. Trees and Binary Trees
Trees are hierarchical data structures with nodes connected by edges. Understanding binary trees, binary search trees, and traversal algorithms like preorder, inorder, and postorder is crucial. Additionally, explore advanced concepts like AVL trees and red-black trees.
5. Graphs
Graphs are non-linear data structures consisting of nodes (vertices) and edges. Familiarize yourself with graph representations, traversal algorithms like BFS (Breadth-First Search) and DFS (Depth-First Search), and graph algorithms such as Dijkstra's algorithm and Kruskal's algorithm.
6. Sorting and Searching Algorithms
Understanding various sorting algorithms like bubble sort, selection sort, insertion sort, merge sort, and quicksort is essential. Additionally, familiarize yourself with searching algorithms like linear search, binary search, and hash-based searching.
7. Dynamic Programming
Dynamic programming involves breaking down a complex problem into smaller overlapping subproblems and solving them individually. Mastering this technique allows you to solve optimization problems efficiently.
These are just a few of the important DSA topics to study. It's crucial to have a solid understanding of these concepts and their applications to perform well in DSA interviews.
Tips to Follow While Preparing for DSA Interviews
Preparing for DSA interviews can be challenging, but with the right approach, you can maximize your chances of success. Here are some tips to keep in mind:
1. Understand the Fundamentals
Before diving into complex algorithms, ensure you have a strong grasp of the fundamentals. Familiarize yourself with basic data structures, common algorithms, and time and space complexities.
2. Practice Regularly
Consistent practice is key to mastering DSA. Solve a wide range of coding problems, participate in coding challenges, and implement algorithms from scratch. Leverage online coding platforms like LeetCode, HackerRank to practice and improve your problem-solving skills.
3. Analyze and Optimize
After solving a problem, analyze your solution and look for areas of improvement. Optimize your code for better time and space complexities. This demonstrates your ability to write efficient and scalable code.
4. Collaborate and Learn from Others
Engage with the coding community, join study groups, and participate in online forums. Collaborating with others allows you to learn different approaches, gain insights, and improve your problem-solving skills.
5. Mock Interviews and Feedback
Simulate real interview scenarios by participating in mock interviews. Seek feedback from experienced professionals or mentors who can provide valuable insights into your strengths and areas for improvement.
Following these tips will help you build a solid foundation in DSA and boost your confidence for interviews.
Conclusion
Mastering DSA is crucial for acing coding interviews and securing your dream job as a software engineer or developer. By studying important DSA topics, following effective preparation tips, and leveraging Tutort Academy's DSA courses, you'll be well-equipped to tackle DSA interviews with confidence. Remember to practice regularly, seek feedback, and stay curious.
Good luck on your DSA journey!
#programming#tutortacademy#tutort#DSA#data structures#data structures and algorithms#algorithm#interview preparation#interview tips
0 notes
Note
Okay so I definitely got carried away after reading this. Carried away, inspired, totally delusional...
@loveshotzz I'm deeply in love with your Older Steve(s) 😩 Thank you for sharing him with us!
Imagine a meet cute with older Steve in the airport…
The first time you see him for the first time while you’re queuing for security.
You’re in separate queues; it’s early and you’re dreaming of the coffee you’re going to order when you get through to departures. You’re sleepily staring into the distance when you catch sight of him. He looks totally effortless in sweats and a plain tshirt under a Nike running jacket. He places his AirPods back in their case before he puts his bag and electronics in the tray like a pro, making polite small talk with the TSA.
Even from a few queues away you can tell he’s a frequent flyer, he knows the drill, though looks less jaded than some of the tell-tale business trippers, less uptight too. You get distracted again, shuffling forward to send your own belongings through the scanners. He melts into the crowd, hold-all in hand. You’ve had grocery store and train station crushes before; handsome airport man is just another anonymous lost love.
It’s a little while later. You see him again ahead of you in the line for coffee. He’s two or three people in front and it’s his height and the broad breadth of his shoulders that you notice. He’s got a baseball cap on over his luscious hair now, one AirPod back in as he orders a large iced americano with an extra shot and a breakfast sandwich. He’s stupidly handsome as he waits for his order; you get a better look at just how dreamy this stranger is. He’s typing on his phone as you wait to order next and you use the few seconds to give him an appreciative once over; the strong arms, the stubble, the fit of his sweats over his thighs. He’s older, early to mid forties but takes care of himself. You bet he uses some fancy moisturiser and eye cream. He’s too far away to prove your hypothesis but he looks like he smells amazing.
As you daydream, your airport crush catches your appreciative look and he smirks a little when your cheeks flame. A lick of heat warms your belly too. Thankfully you’re next up and you manage to order your coffee through the waves of cringe wash over you. You don’t see his gaze drag over your body as he collects his order, or how he contemplates waiting for you until his phone starts ringing and he goes to find a quiet spot to take the call and have his breakfast.
Armed with your own coffee and a little treat (it’s the airport and it’s early, you totally deserve it), you plug yourself in to your music and go in search of your gate. You try not to carry the embarrassment of being caught checking out some random guy in an airport Starbucks (your carry-on is already full, you don’t need that weighing on you too).
You potter through the terminal, browsing the shelves of a book shop, buy a bottle of water for the flight, before settling in a bank of seats near your boarding gate. It’s a tight squeeze between a bored businessman who sits with his legs spread obnoxiously wide and a woman talking far too loud on FaceTime (with no headphones, a crime) but you finally get to indulge in your caffeine and sweet treat fix and rest your feet. You double check your boarding time and scroll Instagram for a few minutes, ignoring the book in your bag (as well as the elbow pressing into your arm on the bored businessman’s side) until you feel something. The weight of a stare, maybe a gaze if you’re feeling romantic about it. A honeyed warmth seeking you out.
It’s him. He’s sitting two rows away, smiling when he catches your eye and gives a little salute that makes you blush again. You place your coffee back down mid sip and swallow, and return his smile. Before you can duck your head, he catches your attention again and nods his head to the seat his bag is (greedily) sitting on. An invitation. One you almost decline until the woman on FaceTime cackles next to you, making you wince. That makes the man smile, shaking his head before beckoning you over again.
Fuck it, you think. it's quieter over there and he’s hot. I’ll never see him again.
You pick up your coffee and wheel your case over to the space he’s vacated for you. He’s got a laptop balanced on his lap and his hold-all is tucked between his feet.
“Hi.” “Hey.”
Your voices overlap, both of you smile. You duck your head and point to the seat. “You sure?”
“Course. It’s all yours. I won’t even say a word. Or man-spread. It was a little douchey to put my bag there anyway.” His voice is like velvet, a warm bath, and when you settle into the seat your suspicions are confirmed. He smells divine, expensive. He flashes another bright white smile before a ping on his laptop drags his attention away.
“Thanks. Again. I’ll not interrupt you working.” You shuffle a little, sipping your coffee as the heavy condensation drips onto your jeans and the cover of the book in your lap.
You urge the butterflies in your stomach to settle, the proximity to an actual Adonis not helping whatsoever. He’s lost the jacket now, and you can see just how strong his arms actually are. His neck (his beautiful neck) has a dusting of freckles and moles beneath the stubble on his jaw and you force yourself to calm down and concentrate on the pages in your lap. You prop your feet on your suitcase and settle in, trying to forget that the man next to you had caught you checking him out less than an hour ago. And yet here you were, sitting next to him at his invitation.
“Sally Rooney, huh?” His voice pulls you away from the same sentence you read at least four times. He’s putting his laptop back in his bag, looking at the cover and then back at you before settling back in his seat. “One of my friends read that one. Really liked it. Even though it made her cry.”
You smile and nod. “Been there. Your friend has good taste, it’s my favourite one. I fancied a re-read.”
He nods, sipping the icy dregs of his coffee before looking right into your eyes. “I’m Steve.” His hands are huge, and you don’t see a wedding ring as he extends a hand to you. It’s warm and soft as you tell him your name and he nods.
“Pretty. Suits you.” You flush again, cheeks warm.
“Cute too,” he murmurs under his breath. “Don’t go shy on me again, sweetheart.” He takes off his hat and ruffles up his hair. "You enjoy your Starbucks?” Oh he had definitely caught you earlier; his face was still handsome despite the smugness.
You laugh, feeling shy but not uncomfortable with him. You have a little while before your flight is called for boarding and so your book is forgotten in favour of Steve.
By the time your gate is called you’re both practically turned sideways to face each other in your uncomfortable airport seats. He’s even more handsome now (if that’s even humanly possible, but you think he might be a little bit ethereal). Flirtation comes easily but not to the extent that he’s creeping you out or making you uncomfortable. He listens when you speak, smiling with encouragement as your shyness ebbs away. In a short amount of time, you feel like you might have known Steve Harrington in a previous life. But maybe that’s the romantic in you.
“That’s my -“ “I better -“
You speak at the same time again before echoing, “Boston?”
Of course Steve is on your flight too. You had learned his dog and best friend’s names but never asked where he was headed to. He stands first, offers you a hand as you unfold your legs to get up. “Ready to rock and roll then?”
You giggle as he shows the few years he has on you and take his hand gratefully. Part of you never wants to let go. It’s been a little over an hour and your airport crush is holding your damn hand. This doesn’t happen to you, the meet cute movie stuff. Your hands eventually part so that you can both make sure you have all of your stuff. You miss how small your hand felt in his, but now isn’t the time to compare hand sizes as an excuse to be close to him. It’s not a high school party, it’s an airport and your flight is boarding behind you.
Together you meander to the gate and get in line. Steve rubs the back of his neck as you double check your passport and seat number.
“So.. see you on the other side maybe? I uh… I have a few work things but I’ll have some free time later in the week if you’d want to grab a drink.” He pushes his hair back before putting his baseball cap back on. His eyes are hopeful beneath the brim and it makes your chest feel warm.
You can hardly believe that this is happening to you and you want to squeal and kick your feet. Somehow you keep your composure, looking up at him through your lashes.
“I’d like that, Steve. I’m visiting a friend and her new baby, so yeah. I’ll need a break from being fairy godmother.”
His smile is like sunshine when you say his name. “Awesome.” It makes you smile too.
You swap numbers as you board; Steve’s in first class (which he’s almost apologetic for, calling himself a ‘total d-bag’ again) but he’s caught your seat number so that he can send you a drink mid-flight. He squeezes your hand before you part ways.
He’s reluctant to let go this time and drops a wink your way before you say goodbye (for now). You try not to be a little jealous of his comfy seat and extra legroom but after spending time with Steve you feel like you’re floating.
You’re just settled as a text buzzes in from him.
Hi :) See you on the other side sweetheart
Then another.
This is Steve btw :P
As if he hadn’t typed his name into your phone himself. You smile and heart react to his message.
Hi, hope you have a comfy flight. See you in Boston x
Happy vacation! Imagine Colours Steve in the airport? Such an airport dad omg
God, he’d look so good in his casual airport fit. Hair a little messy cause he took a quick shower in the morning, he didn’t have enough time to shave so he’s got his salt and pepper five o’clock shadow. It’s too early for him to fiddle with contacts (he sleeps on the plane anyway, arms crossed over his chest the whole time) so he’s wearing his wire rim glasses.
I’m sure he’s wearing some basketball shorts with a pair of clean Nike sneakers, an undershirt and a light running jacket. He’s checking his emails in line at Starbucks where he orders a black iced coffee.
#steve harrington#steve harrington x reader#older!steve harrington#stranger things#i really got carried away here...#bangaveragefic
231 notes
·
View notes
Text
C# - Breadth First Search (BFS) using Queue
C# – Breadth First Search (BFS) using Queue
In this article, we will write a C# program to implement Breadth First Search (BFS) using Queue
Breadth-first search (BFS) is an algorithm for traversing or searching tree or graph data structures. It starts at the tree root (or some arbitrary node of a graph) and explores the neighbor nodes first, before moving to the next level neighbors.
using System; using System.Collections.Generic; using…
View On WordPress
0 notes
Text
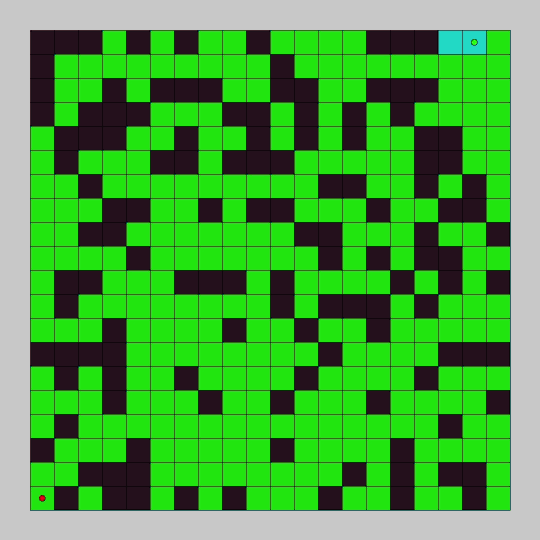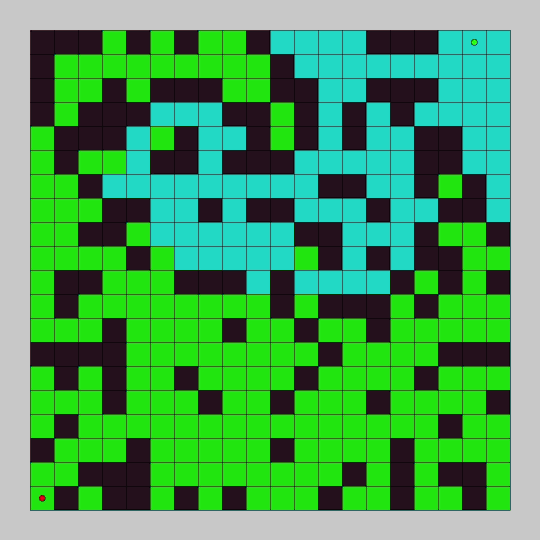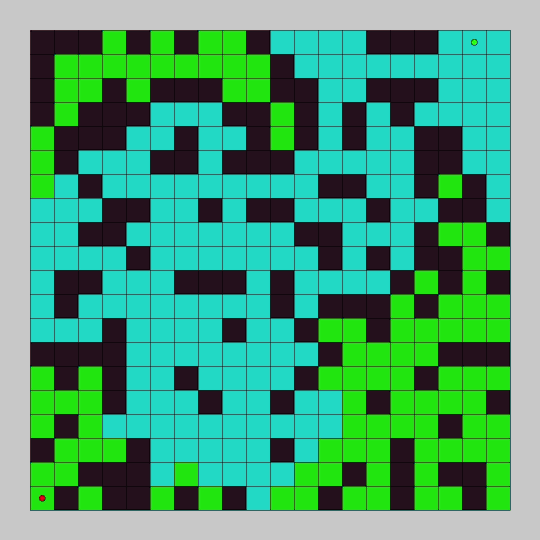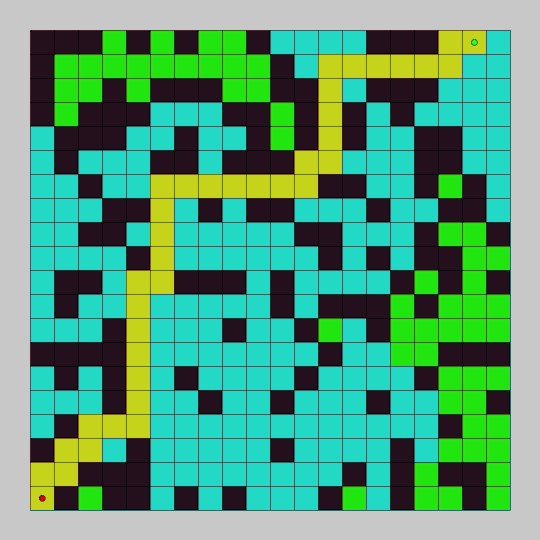
Learn how to explore a grid and find a goal point with breadth first search in this pathfinding tutorial. You will use Processing and Java to code the breadth first search pathfinding algorithm and create a graphical demo so you can see it in action.
In the last tutorial, we programmed depth first search and watched it explore a node graph. In this tutorial we will program breadth first search and watch it explore a grid.
The breadth first search algorithm will add every unexplored adjacent node to a queue, and explore all of the added nodes in sequence. For each node explored, it will continue to add the adjacent unexplored nodes to the queue. It will continue to do this until the goal is found or all connected nodes have been explored.
#gamedev#indiedev#maze#pathfinding#game development#coding#creative coding#programming#Java#processing#search algorithm#tutorial#education#breadth first search#grid
18 notes
·
View notes
Text
Implementation
Hardest part of any programming assignment. In
Plan your program
????
Profit!
Implementation is very much the ???? line.
Today's task is making something that can find its way around on a map and generate driving directions.
And it's worth breaking down what we're asking for, here.
For reasonably good first-try pathfinding, Depth-First Search (especially if you have the starting coordinates) works well, but if we want to be consistently finding the shortest route and don't mind a bump in how many nodes we look at to get our answer, Breadth-First Search will give us better results more easily. I've got a theory of how one could do DFS and modify it by slicing it up and testing each sub-path BUT a) that's literally only theoretical at the moment and b) I'm pretty sure that if I can get it working and it's superior to BFS for this task it'll still be harder to code, like how working with a search tree is more coding than working with a list.
TL;DR: BFS for now.
Breadth-First just means we put new info about our surroundings at the back of a queue and work with what we already found first. If you've got a robot in an open field (of what it sees as 5x5' squares because you apparently taught it spatial awareness using tabletop RPGs), its process will be,
Check for paths: North, East, South, West. We check both "has this space already been visited" and "can I walk here." If it's already been visited then going there will never be the shortest path because you're doubling back. Refusing to backtrack also precludes one possible kind of infinite loop.
All the valid paths get added to the back of the queue in the order they're looked at. They're also added to the "visited" list so that you can't have accidental double-visits: Picture 3 houses in a triangle. You check for paths, and add the paths from A to B and C. Then you go to B because it's next in the queue. If you haven't already counted C as visited it'll be added to the queue a second time. Note that if your question isn't "shortest path" you might want to record the presence of multiple paths to a goal including the longer ones.
Then you repeat this process from each location in the queue. So if you were at 0,0 your queue would be 0,1 - 1,0 - 0,-1 - -1,0 and then you'd go to 0,1 and add 0,2 and 1,1 and -1,1 to the back of the queue, and then you'd go to 1,0 and because you already added 1,1 to "visited" you wouldn't add it again, and so on.
Each time you do this you'd also check whether you were standing on the goal. If so you could return the path you took to get where you are as your driving directions, because the nature of BFS is to find the smallest number of hops. It's worth noting that if all hops are not created equal in terms of length you may need a different approach. I predict we'll get into weighted edges on graphs in a later week of this course.
Anyway you have two possible outcomes for this loop. If the queue runs out and you haven't found the goal, it's not on the map - or at least, isn't accessible with your standard movement options.
0 notes
Text
CSC220 Lab12 Graph Algorithms
The goal of this week’s lab is: Practice working with graphs Practice working with stacks and queues Practice using breadth-first search (BFS) and depth-first search (DFS) Practice using a nested class Practice I/O This week, you are asked to write a program to help Pacman solve mazes. We will apply BFS and DFS search strategies to find a path from one location to…

View On WordPress
0 notes
Text
Project 1: The Rat Pack Solution
Project 1: The Rat Pack Solution
Educational Objectives: After completing this assignment, the student should be able to accomplish the following: Use ADT Queue to control breadth-first search Use bitwise operations to extract individual bits from words Set up a general maze solving system Write applications involving multiple interacting classes and objects Operational Objectives: Design and implement a simulation that…

View On WordPress
0 notes
Text
BFS Algorithm
Breadth-First Search Algorithm
Breadth-First Search Algorithm or BFS is the most widely utilized method.
BFS is a graph traversal approach in which you start at a source node and layer by layer through the graph, analyzing the nodes directly related to the source node. Then, in BFS traversal, you must move on to the next-level neighbor nodes.
According to the BFS, you must traverse the graph in a breadthwise direction:
· To begin, move horizontally and visit all the current layer’s nodes.
· Continue to the next layer.
Breadth-First Search uses a queue data structure to store the node and mark it as “visited” until it marks all the neighboring vertices directly related to it. The queue operates on the First In First Out (FIFO) principle, so the node’s neighbors will be viewed in the order in which it inserts them in the node, starting with the node that was inserted first.
Read More
Why Do You Need Breadth-First Search Algorithm?
There are several reasons why you should use the BFS Algorithm to traverse graph data structure. The following are some of the essential features that make the BFS algorithm necessary:
· The BFS algorithm has a simple and reliable architecture.
· The BFS algorithm helps evaluate nodes in a graph and determines the shortest path to traverse nodes.
· The BFS algorithm can traverse a graph in the fewest number of iterations possible.
· The iterations in the BFS algorithm are smooth, and there is no way for this method to get stuck in an infinite loop.
· In comparison to other algorithms, the BFS algorithm’s result has a high level of accuracy.
In this tutorial, next, you will look at the pseudocode for the breadth-first search algorithm.
Pseudocode Of Breadth-First Search Algorithm
The breadth-first search algorithm’s pseudocode is:
Read More
Bredth_First_Serach( G, A ) // G ie the graph and A is the source node
Let q be the queue
q.enqueue( A ) // Inserting source node A to the queue
Mark A node as visited.
While ( q is not empty )
B = q.dequeue( ) // Removing that vertex from the queue, which will be visited by its neighbour
Processing all the neighbors of B
For all neighbors of C of B
If C is not visited, q. enqueue( C ) //Stores C in q to visit its neighbour
Mark C a visited
For a better understanding, you will look at an example of a breadth-first search algorithm later in this tutorial.
Example of Breadth-First Search Algorithm
In a tree-like structure, graph traversal requires the algorithm to visit, check, and update every single un-visited node. The sequence in which graph traversals visit the nodes on the graph categorizes them.
The BFS algorithm starts at the first starting node in a graph and travels it entirely. After traversing the first node successfully, it visits and marks the next non-traversed vertex in the graph.
Step 1: In the graph, every vertex or node is known. First, initialize a queue.
Step 2: In the graph, start from source node A and mark it as visited.
Step 3: Then you can observe B and E, which are unvisited nearby nodes from A. You have two nodes in this example, but here choose B, mark it as visited, and enqueue it alphabetically.
Step 4: Node E is the next unvisited neighboring node from A. You enqueue it after marking it as visited.
Step 5: A now has no unvisited nodes in its immediate vicinity. As a result, you dequeue and locate A.
Read More
Step 6: Node C is an unvisited neighboring node from B. You enqueue it after marking it as visited.
Step 7: Node D is an unvisited neighboring node from C. You enqueue it after marking it as visited.
Step 8: If all of D’s adjacent nodes have already been visited, remove D from the queue.
Step 9: Similarly, all nodes near E, B, and C nodes have already been visited; therefore, you must remove them from the queue.
Step 10: Because the queue is now empty, the bfs traversal has ended.
Complexity Of Breadth-First Search Algorithm
The time complexity of the breadth-first search algorithm : The time complexity of the breadth-first search algorithm can be stated as O(|V|+|E|) because, in the worst case, it will explore every vertex and edge. The number of vertices in the graph is |V|, while the edges are |E|.
The space complexity of the breadth-first search algorithm : You can define the space complexity as O(|V|), where |V| is the number of vertices in the graph, and different data structures are needed to determine which vertices have already been added to the queue. This is also the space necessary for the graph, which varies depending on the graph representation used by the algorithm’s implementation.
You will see some bfs algorithm applications now that you’ve grasped the complexity of the breadth-first search method.
Application Of Breadth-First Search Algorithm
The breadth-first search algorithm has the following applications:
· For Unweighted Graphs, You Must Use the Shortest Path and Minimum Spacing Tree.
Read More
The shortest path in an unweighted graph is the one with the fewest edges. You always reach a vertex from a given source using the fewest amount of edges when utilizing breadth-first. In unweighted graphs, any spanning tree is the Minimum Spanning Tree, and you can identify a spanning tree using either depth or breadth-first traversal.
· Peer to Peer Network
Breadth-First Search is used to discover all neighbor nodes in peer-to-peer networks like BitTorrent.
· Crawlers in Search Engine
Crawlers create indexes based on breadth-first. The goal is to start at the original page and follow all of the links there, then repeat. Crawlers can also employ Depth First Traversal. However, the benefit of breadth-first traversal is that the depth or layers of the created tree can be limited.
· Social Networking Websites
You can use a breadth-first search to identify persons within a certain distance ‘d’ from a person in social networks up to ‘d’s levels.
· GPS Navigation System
To find all nearby locations, utilize the breadth-first search method.
· Broadcasting Network
A broadcast packet in a network uses breadth-first search to reach all nodes.
· Garbage Collection
Cheney’s technique uses the breadth-first search for duplicating garbage collection. Because of the better locality of reference, breadth-first search is favored over the Depth First Search algorithm.
· Cycle Detection in Graph
Cycle detection in undirected graphs can be done using either Breadth-First Search or Depth First Search. BFS can also be used to find cycles in a directed graph.
· Identifying Routes
To see if there is a path between two vertices, you can use either Breadth-First or Depth First Traversal.
· Finding All Nodes Within One Connected Component
To locate all nodes reachable from a particular node, you can use either Breadth-First or Depth First Traversal.
Read More
Code Implementation of Breadth-First Search Algorithm
Breadth-First Search Algorithm Code Implementation:
#include<stdio.h>
#include<conio.h>
#include<stdlib.h>
int twodimarray[10][10],queue[10],visited[10],n,i,j,front=0,rear=-1;
void breadthfirstsearch(int vertex) // breadth first search function
{
for (i=1;i<=n;i++)
if(twodimarray[vertex][i] && !visited[i])
queue[++rear]=i;
if(front<=rear)
{
visited[queue[front]]=1;
breadthfirstsearch(queue[front++]);
}
}
int main() {
int x;
printf(“\n Enter the number of vertices:”);
scanf(“%d”,&n);
for (i=1;i<=n;i++) {
queue[i]=0;
visited[i]=0;
}
printf(“\n Enter graph value in form of matrix:\n”);
for (i=1;i<=n;i++)
for (j=1;j<=n;j++)
scanf(“%d”,&twodimarray[i][j]);
printf(“\n Enter the source node:”);
scanf(“%d”,&x);
breadthfirstsearch(x);
printf(“\n The nodes which are reachable are:\n”);
for (i=1;i<=n;i++)
if(visited[i])
printf(“%d\t”,i);
else
printf(“\n Breadth first search is not possible”);
getch();
}
1 note
·
View note
Text
BFS Algorithm
Breadth-First Search Algorithm
Breadth-First Search Algorithm or BFS is the most widely utilized method.
BFS is a graph traversal approach in which you start at a source node and layer by layer through the graph, analyzing the nodes directly related to the source node. Then, in BFS traversal, you must move on to the next-level neighbor nodes.
According to the BFS, you must traverse the graph in a breadthwise direction:
· To begin, move horizontally and visit all the current layer's nodes.
· Continue to the next layer.
Breadth-First Search uses a queue data structure to store the node and mark it as "visited" until it marks all the neighboring vertices directly related to it. The queue operates on the First In First Out (FIFO) principle, so the node's neighbors will be viewed in the order in which it inserts them in the node, starting with the node that was inserted first.
Read More
Why Do You Need Breadth-First Search Algorithm?
There are several reasons why you should use the BFS Algorithm to traverse graph data structure. The following are some of the essential features that make the BFS algorithm necessary:
· The BFS algorithm has a simple and reliable architecture.
· The BFS algorithm helps evaluate nodes in a graph and determines the shortest path to traverse nodes.
· The BFS algorithm can traverse a graph in the fewest number of iterations possible.
· The iterations in the BFS algorithm are smooth, and there is no way for this method to get stuck in an infinite loop.
· In comparison to other algorithms, the BFS algorithm's result has a high level of accuracy.
In this tutorial, next, you will look at the pseudocode for the breadth-first search algorithm.
Pseudocode Of Breadth-First Search Algorithm
The breadth-first search algorithm's pseudocode is:
Read More
Bredth_First_Serach( G, A ) // G ie the graph and A is the source node
Let q be the queue
q.enqueue( A ) // Inserting source node A to the queue
Mark A node as visited.
While ( q is not empty )
B = q.dequeue( ) // Removing that vertex from the queue, which will be visited by its neighbour
Processing all the neighbors of B
For all neighbors of C of B
If C is not visited, q. enqueue( C ) //Stores C in q to visit its neighbour
Mark C a visited
For a better understanding, you will look at an example of a breadth-first search algorithm later in this tutorial.
Example of Breadth-First Search Algorithm
In a tree-like structure, graph traversal requires the algorithm to visit, check, and update every single un-visited node. The sequence in which graph traversals visit the nodes on the graph categorizes them.
The BFS algorithm starts at the first starting node in a graph and travels it entirely. After traversing the first node successfully, it visits and marks the next non-traversed vertex in the graph.
Step 1: In the graph, every vertex or node is known. First, initialize a queue.
Step 2: In the graph, start from source node A and mark it as visited.
Step 3: Then you can observe B and E, which are unvisited nearby nodes from A. You have two nodes in this example, but here choose B, mark it as visited, and enqueue it alphabetically.
Step 4: Node E is the next unvisited neighboring node from A. You enqueue it after marking it as visited.
Step 5: A now has no unvisited nodes in its immediate vicinity. As a result, you dequeue and locate A.
Read More
Step 6: Node C is an unvisited neighboring node from B. You enqueue it after marking it as visited.
Step 7: Node D is an unvisited neighboring node from C. You enqueue it after marking it as visited.
Step 8: If all of D's adjacent nodes have already been visited, remove D from the queue.
Step 9: Similarly, all nodes near E, B, and C nodes have already been visited; therefore, you must remove them from the queue.
Step 10: Because the queue is now empty, the bfs traversal has ended.
Complexity Of Breadth-First Search Algorithm
The time complexity of the breadth-first search algorithm : The time complexity of the breadth-first search algorithm can be stated as O(|V|+|E|) because, in the worst case, it will explore every vertex and edge. The number of vertices in the graph is |V|, while the edges are |E|.
The space complexity of the breadth-first search algorithm : You can define the space complexity as O(|V|), where |V| is the number of vertices in the graph, and different data structures are needed to determine which vertices have already been added to the queue. This is also the space necessary for the graph, which varies depending on the graph representation used by the algorithm's implementation.
You will see some bfs algorithm applications now that you’ve grasped the complexity of the breadth-first search method.
Application Of Breadth-First Search Algorithm
The breadth-first search algorithm has the following applications:
· For Unweighted Graphs, You Must Use the Shortest Path and Minimum Spacing Tree.
Read More
The shortest path in an unweighted graph is the one with the fewest edges. You always reach a vertex from a given source using the fewest amount of edges when utilizing breadth-first. In unweighted graphs, any spanning tree is the Minimum Spanning Tree, and you can identify a spanning tree using either depth or breadth-first traversal.
· Peer to Peer Network
Breadth-First Search is used to discover all neighbor nodes in peer-to-peer networks like BitTorrent.
· Crawlers in Search Engine
Crawlers create indexes based on breadth-first. The goal is to start at the original page and follow all of the links there, then repeat. Crawlers can also employ Depth First Traversal. However, the benefit of breadth-first traversal is that the depth or layers of the created tree can be limited.
· Social Networking Websites
You can use a breadth-first search to identify persons within a certain distance 'd' from a person in social networks up to 'd's levels.
· GPS Navigation System
To find all nearby locations, utilize the breadth-first search method.
· Broadcasting Network
A broadcast packet in a network uses breadth-first search to reach all nodes.
· Garbage Collection
Cheney's technique uses the breadth-first search for duplicating garbage collection. Because of the better locality of reference, breadth-first search is favored over the Depth First Search algorithm.
· Cycle Detection in Graph
Cycle detection in undirected graphs can be done using either Breadth-First Search or Depth First Search. BFS can also be used to find cycles in a directed graph.
· Identifying Routes
To see if there is a path between two vertices, you can use either Breadth-First or Depth First Traversal.
· Finding All Nodes Within One Connected Component
To locate all nodes reachable from a particular node, you can use either Breadth-First or Depth First Traversal.
Read More
Code Implementation of Breadth-First Search Algorithm
Breadth-First Search Algorithm Code Implementation:
#include<stdio.h>
#include<conio.h>
#include<stdlib.h>
int twodimarray[10][10],queue[10],visited[10],n,i,j,front=0,rear=-1;
void breadthfirstsearch(int vertex) // breadth first search function
{
for (i=1;i<=n;i++)
if(twodimarray[vertex][i] && !visited[i])
queue[++rear]=i;
if(front<=rear)
{
visited[queue[front]]=1;
breadthfirstsearch(queue[front++]);
}
}
int main() {
int x;
printf("\n Enter the number of vertices:");
scanf("%d",&n);
for (i=1;i<=n;i++) {
queue[i]=0;
visited[i]=0;
}
printf("\n Enter graph value in form of matrix:\n");
for (i=1;i<=n;i++)
for (j=1;j<=n;j++)
scanf("%d",&twodimarray[i][j]);
printf("\n Enter the source node:");
scanf("%d",&x);
breadthfirstsearch(x);
printf("\n The nodes which are reachable are:\n");
for (i=1;i<=n;i++)
if(visited[i])
printf("%d\t",i);
else
printf("\n Breadth first search is not possible");
getch();
}
1 note
·
View note
Text
The Breadth-First Search Algorithm
Graphs can be traversed in a depth-first or breadth-first manner. The first one is particularly useful when your data is a DAG (directed, acyclical graph), but both can be applied to any given kind of graph, including trees.
Consider this example:
This is a graph with 9 nodes, which I have key colored to show the depth of every layer of nodes. Hopefully this clears out the topology a bit. This graph can be represented as a 9 x 9 adjacency matrix as shown above (if you have N nodes, necessarily you need N x N size in your matrix).
The key to traversing the graph in a breadth-first manner is the implementation of two auxiliary data structures:
An N-sized array to keep track of what nodes you have already visited in your traversal, to avoid cycles when going down the graph by layers.
A queue of nodes of dynamic size, which will queue the nodes in order as you visit them, and dequeue them as you traverse down.
So in this example, you would do this, if you wished to traverse the tree starting from node 0:
Enqueue 0
Dequeue 0
Enqueue all its children, 1, 2, 3 (queue = 1, 2, 3)
Add 0 to output
Mark 0 as visited
Dequeue 1
If not visited yet, enqueue all its children, 4 and 5 (queue = 2, 3, 4, 5)
Add 1 to output
Mark 1 as visited
Dequeue 2
If not visited yet, enqueue all its children, 3 and 6 (queue = 3, 4, 5, 6) ... REPEAT UNTIL THE QUEUE IS EMPTY and all nodes have been visited
This is a sample implementation:
import java.util.Queue; import java.util.ArrayDeque; import java.util.List; import java.util.ArrayList; public class Main { public static int N = 9; public static void main(String[] args) { int[][] graph = new int[N][N]; graph[0][1] = 1; graph[0][2] = 1; graph[0][3] = 1; graph[1][4] = 1; graph[1][5] = 1; graph[2][3] = 1; graph[2][6] = 1; graph[3][7] = 1; graph[3][8] = 1; System.out.println(bfs(graph, 0).toString()); } private static List bfs(int[][] graph, int startNode) { List<Integer> result = new ArrayList<>(); //visited array of N elements to avoid cycles boolean[] visited = new boolean[N]; Queue<Integer> queue = new ArrayDeque<>(); int current = startNode; queue.add(current); visited[startNode] = true; while (!queue.isEmpty()) { int currentNode = queue.poll(); result.add(currentNode); // Explore all neighbors of the current node for (int i = 0; i < graph[currentNode].length; i++) { if (graph[currentNode][i] == 1 && !visited[i]) { queue.add(i); visited[i] = true; } } } return result; } }
0 notes